

Azure Sentinel is Microsoft’s cloud native SIEM/SOAR and is quickly becoming the security tool of choice for many security teams around the world. It is highly capable and very extendable, which we will cover in more detail within this blog.
Introduction
Azure Sentinel is Microsoft’s cloud native SIEM/SOAR and is quickly becoming the security tool of choice for many security teams around the world. It is highly capable and very extendable, which we will cover in more detail within this blog.
It connects natively to numerous Microsoft Products through built in, easy to connect, data connectors
It also has the capability of automation through Playbooks. You may have seen something like these across other Microsoft products in the guise of Microsoft Flow or Logic Apps.
Playbooks allow you run automation steps to schedule, automate, and orchestrate tasks and workflows without the need to write bespoke applications. They are provisioned within the cloud, so you do not need to think about separate infrastructure requirements.
They have distinct advantages within security monitoring as they are quick to develop and simple to understand. This can help mitigate any skills gaps within the team as the users will not be required to have a prior knowledge of any specific programming languages such a python, C# and PowerShell.
The Problem?
Azure Sentinel is a great tool right out of the box, but currently lacks some key features. One of these is the ability to extract all the metadata related to security incidents in a simple and effective way.
This is useful if you want to monitor KPIs, the effectiveness of sentinel detection or even just providing a simple data dump. The data could be imported into a variety of tools such as PowerBI or a custom workbook.
Searching through the Microsoft GitHub page and looking at some community blogs we came across the Azure Sentinel API (currently still in preview). This API has methods for retrieving incident metadata and importantly also has methods to pull corresponding comment data for each incident.
Now we could have created some local scripts to pull the required information, format the data and it would have been job done; but that’s not very collaborative or cloud centric, so we decided a Playbook would be a perfect fit.
The Solution…
It took a few iterations and some trial and error, but we finally came up with a functioning solution.
Find the templated version of this Playbook on the official Microsoft Sentinel GitHub.
You can find an annotated guide to the playbook included below.
Prerequisites
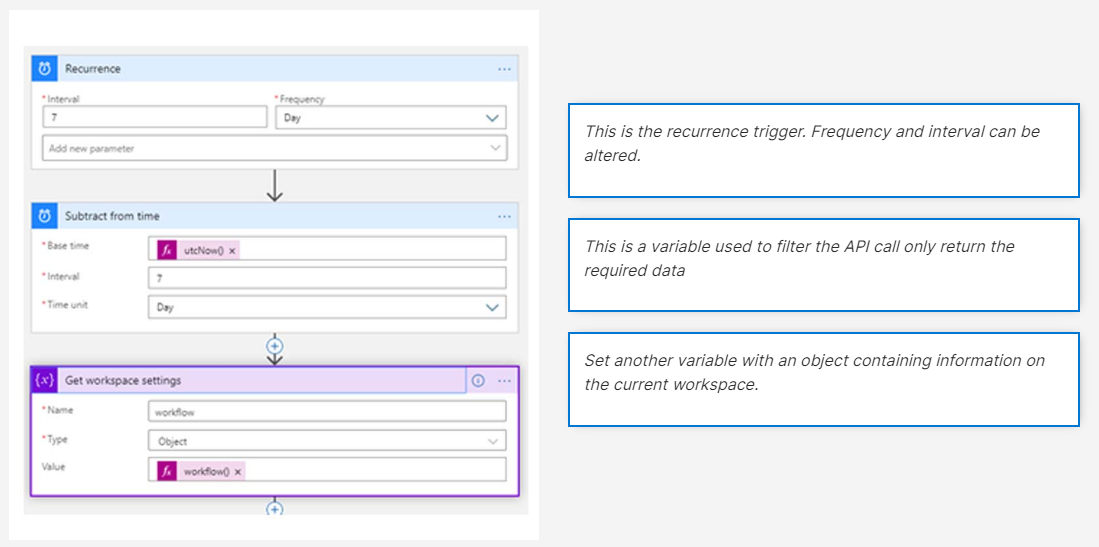
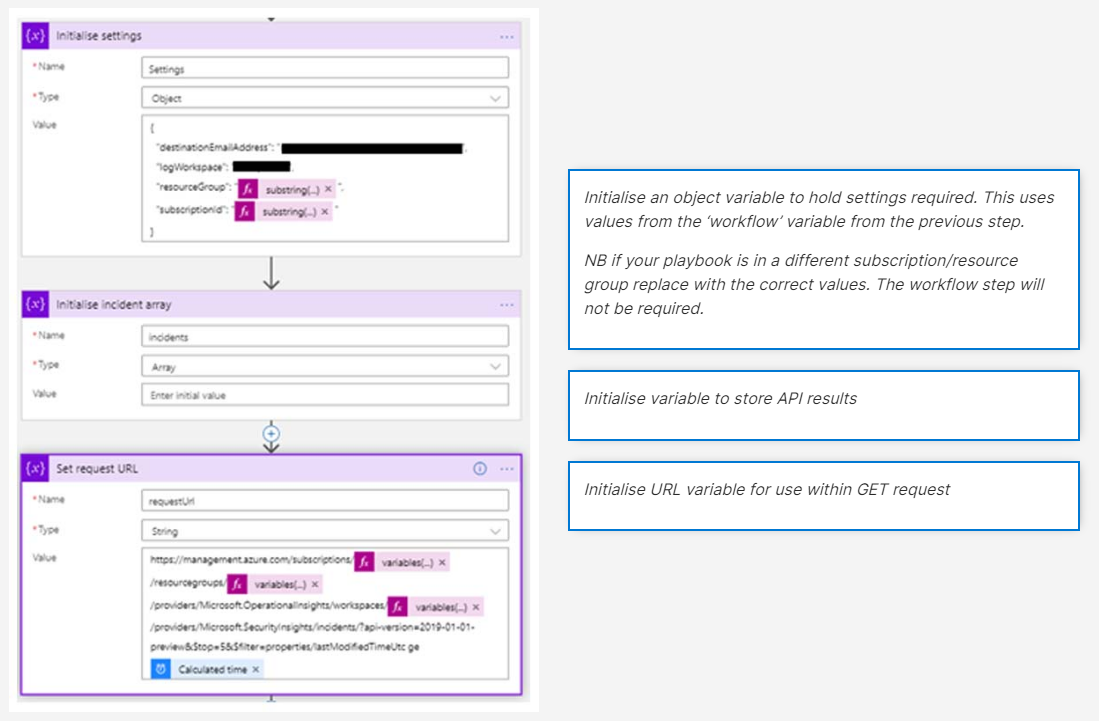
- This playbook requires Managed Identity. You will need to turn on managed identity for this Playbook. You will then need to Assign RBAC ‘Log Analytic Reader’ role to the Logic App at the required level.
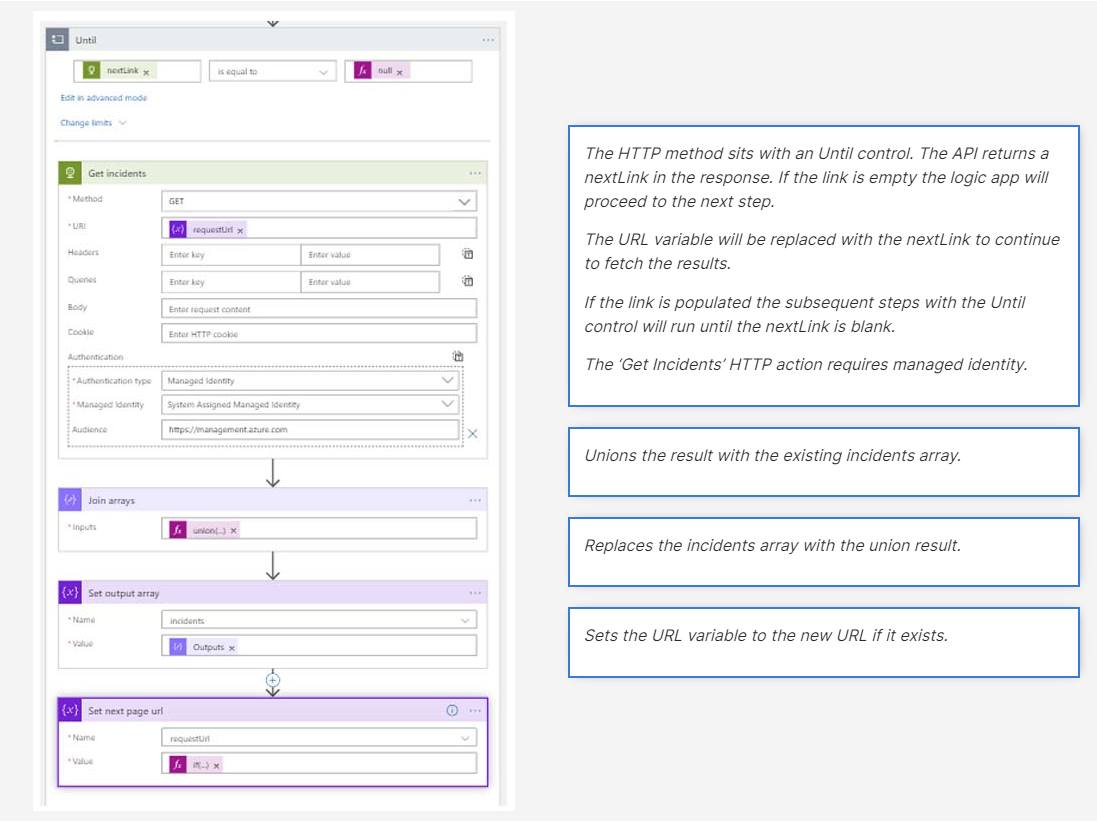
- The next step is to make a GET request to the security incident’s API. The API supports pagination so we will need to handle this within the playbook. Therefore, we have created a URL variable and incidents array variable in the previous steps.
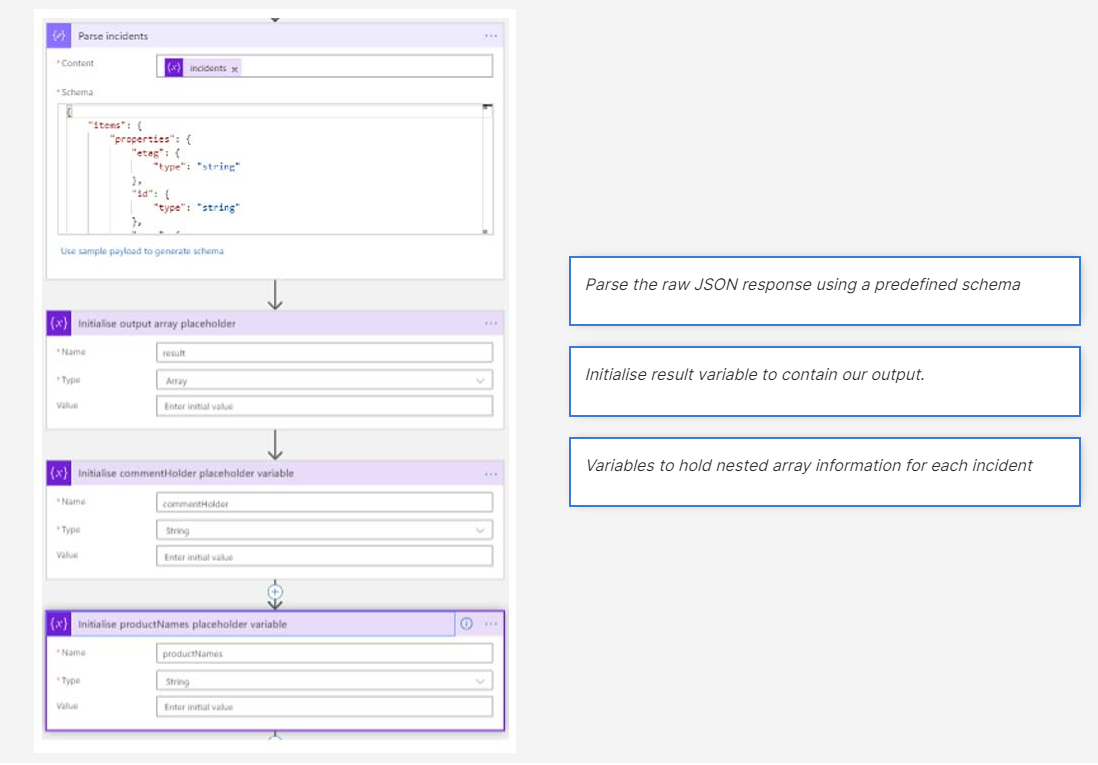
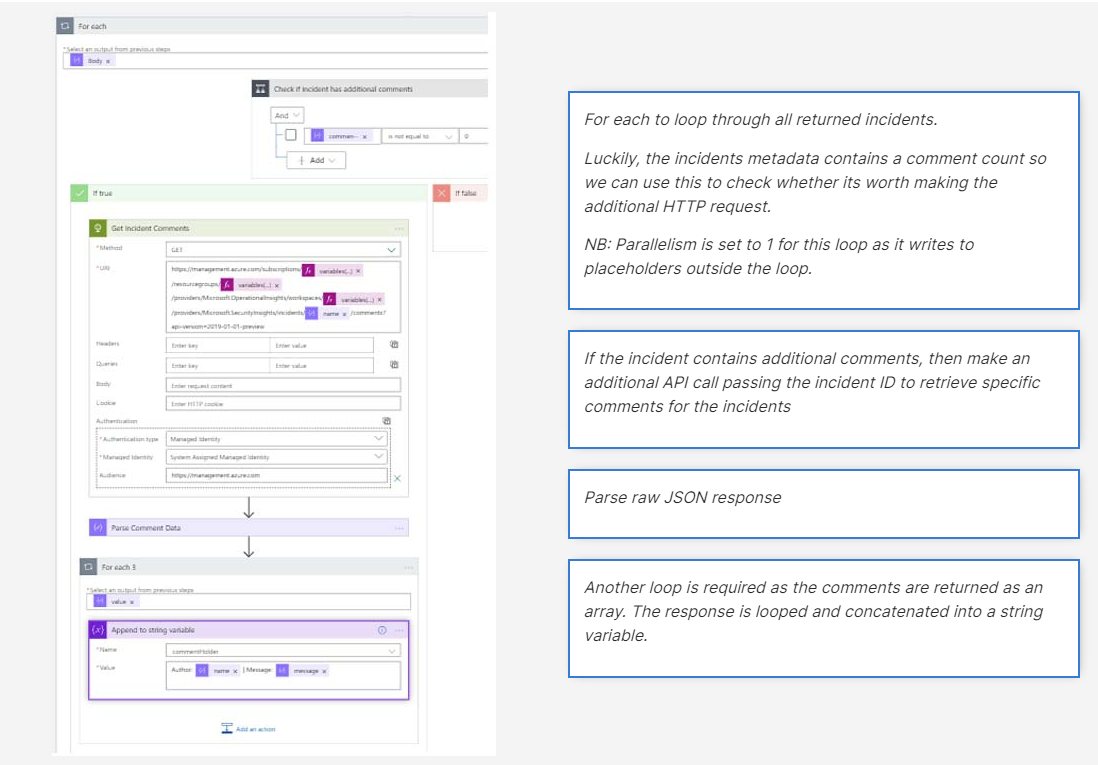
- At this stage we now have all the required incidents from the API into the incidents array placeholder. We now need to parse this data into something meaningful and extract any corresponding comments for each incident.
- Now we have parsed the data and set up the placeholders we loop through each incident and attempt to pull any corresponding comments. If we do not find any comments, we continue with step 5.
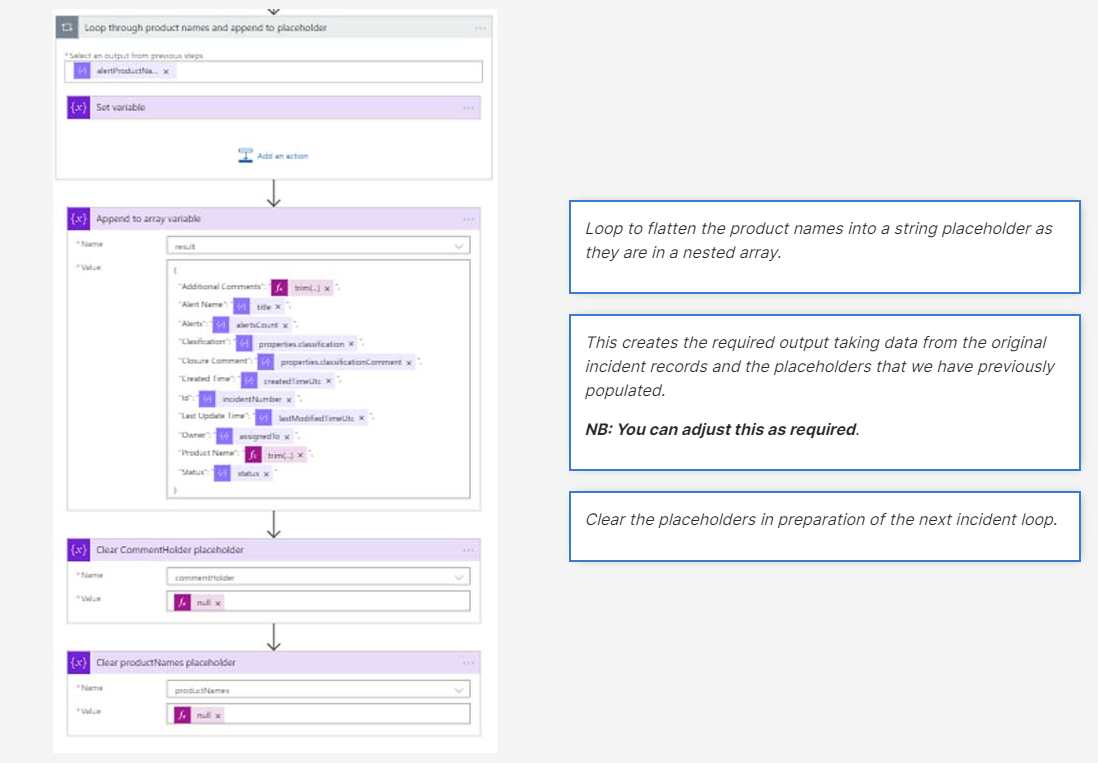
- We are still within the original for each loop at this stage. The next step is to extract the required fields from the incidents record and any additional comments if found.
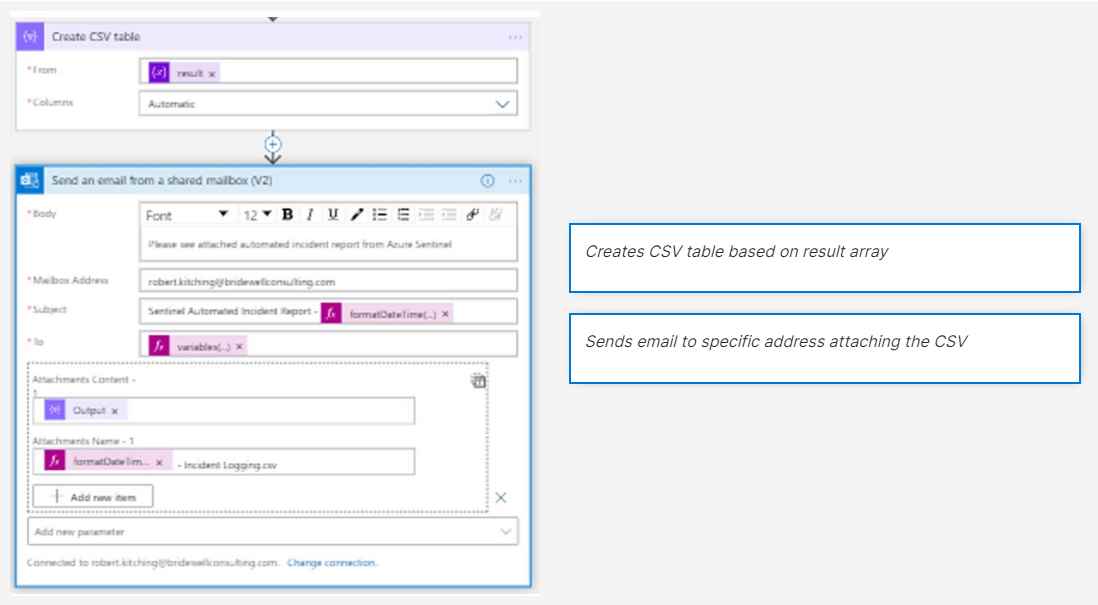
- Once the loop has exited, we should now have a result output array containing the data we require. The next step is to convert the array to a CSV table and to email to a specific address.
Conclusion
Azure Sentinel may not have all the required features you need straight out of the box, but with some effort and understanding you can tweak it to your custom requirements. Breaking down the problem into small steps will help understand how it pieces together.
Microsoft and the wider community are also having a big part to play with various contributions to improve its capabilities. You can find any Bridewell and community contributions on the official Microsoft Sentinel GitHub page.
Need help with Azure Sentinel?
At Bridewell we have a number of Senior Consultants who are highly skilled Azure Sentinel specialists and if you have any questions or would like further information please get in touch.
Author
Robert Kitching
Senior Lead Security Development Engineer
Linkedin Blogs
Blogs